如何实现一个高性能排行榜 2024-07-09 默认分类 暂无评论 2044 次阅读 # 高性能排行榜 <h2><a class="cl-offset" name="cl-1"></a>需求分析 </h2> 项目需要实现一个基于分数统计的排行榜 假设日活跃用户数量为1个亿 每个用户登录后可以看到自己在名次 同时展示一个自己名次前后5名的其他用户 并显示其他人的分数 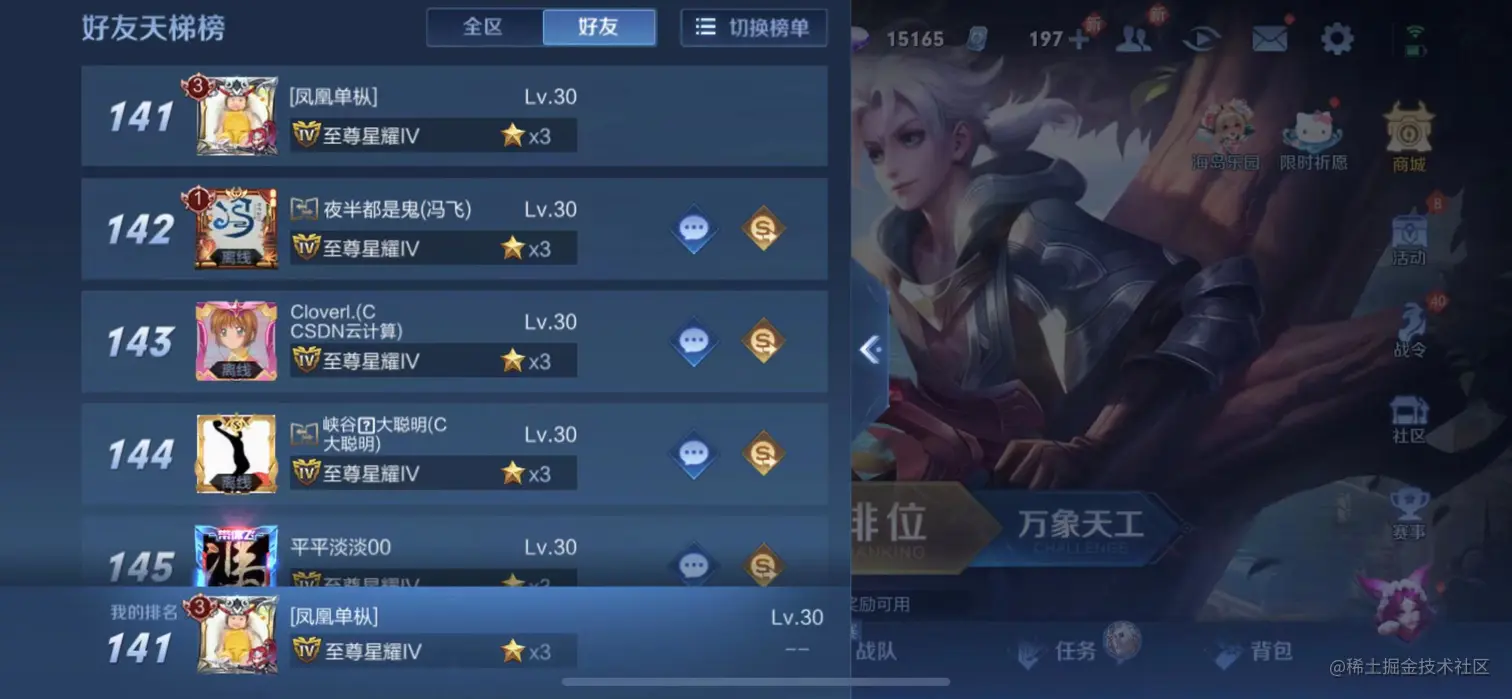 初步分析 这里用到以下几个接口 - POST /api/score/add 增加用户积分 供游戏结算使用 - GET /api/rank/position 获取排行榜名次 - GET /api/rank/range 获取排行榜区间 <h3><a class="cl-offset" name="cl-2"></a>增加用户积分 </h3> 1. 更新ZSet (lua脚本解决并发问题) 2. 异步写入DB (失败记录日志, 后期补偿) > 这里可以使用MQ 将DB的写入过程放到后台 > 由额外的消费进程进行处理 <h3><a class="cl-offset" name="cl-3"></a>获取TopN </h3> 1. 尝试从本地缓存>redis缓存中读取 2. 若读取失败 则从DB中读取 并回写到本地缓存及redis缓存中 <h2><a class="cl-offset" name="cl-4"></a>特点分析 </h2> 1. 这个场景能够容忍 一定的数据误差 2. 可以放弃一定的时效性 来实现更高的并发访问性能 (这里只实现了获取排行榜接口的高并发) 若要使点赞同样支持高并发 需要引入MQ 将点赞事件落入队列 同时我们可以采用以下策略来实现更高的访问性能和高可用性 <h3><a class="cl-offset" name="cl-5"></a>多级缓存 </h3> 利用多级缓存 1. 本地缓存 2. redis缓存 通过Zset保存排行榜数据 3. DB作为redis数据的备份 每次重新启动服务时会将DB的数据写入redis作为基础数据 <h3><a class="cl-offset" name="cl-6"></a>降级策略 </h3> 本文使用redis作为主要操作对象 当redis发生宕机时 设置一个无过期时间的 本地缓存(从DB中获取) 作为降级方案 *多级缓存策略-时序图* <img class="post-content-img" src="http://res.i-cooltea.top/image/bb428e7a3ae49c358c7887d7cd7702ed.png"/> <img class="post-content-img" src="http://res.i-cooltea.top/image/648f3a4fcedb3248b7d2528065c39882.png"/> <h1><a class="cl-offset" name="cl-7"></a>如何应对海量数据? </h1> <h2><a class="cl-offset" name="cl-8"></a>策略1 压缩数据量 </h2> 1. **淘汰历史数据** 假设我需要按周统计排名 那就按WeekN 作为键值 排名变更时 将当前的记录写入weekN中 而week(N-1) 的数据将会自动淘汰 week1保存第1周的记录 到week2后自动清零 在week1和week2的交界处 提前将week1的历史记录写入week2中 2. **淘汰top1000之后的数据** 若当前操作的数据 远远小于topN的分数 则不将其记录到排行榜中 <h2><a class="cl-offset" name="cl-9"></a>策略2 数据分片 </h2> **1.按分数区间分片** 假设数据知道自己自身的分数 可以通过可以通过分数区间分段 将数据均匀分布到不同的桶中 假设我有一个历史排名可以参考 那么就通过历史排名 将数据落入对应的分数段所对应的Zset桶中 (如果存在分段不均的情况则可以 可以单独维护一个区间和桶的映射关系 每次写入前先通过区间映射确定桶的位置 ) > 注意: 数据分桶后只能保证桶内元素严格有序 不同的桶之间的排序可能存在一定的分片误差 **2. 按业务的逻辑分片** 按区域可以划分 华南 华北 华中 按省份可以划分 广东 湖南 湖北... 不同的区间之间相互独立 互不干扰 <h2><a class="cl-offset" name="cl-10"></a>策略3 数据预处理 </h2> 设定一个后台定时任务 间隔30s 从后台查找top100个记录 并将其写入本地缓存中 设定过期时间为30s <h1><a class="cl-offset" name="cl-11"></a>ZSet 底层数据结构 </h1> 提到排行榜可能大部分人都想到的是用zset 那么这是为什么呢? 原因是ZSet采用了 skip-list 来存储数据 可以说是解决排行榜问题的最匹配的数据结构了 在数据量很大的时候 通过多级索引结构可以快速定位到目前元素所在位置 同时最底层的数据通过双向链表相互链接可以很方便地实现前后 区间查找 <img class="post-content-img" src="http://res.i-cooltea.top/image/20240809230205.png"/> <h1><a class="cl-offset" name="cl-12"></a>参考链接 </h1> [Skip List--跳表(全网最详细的跳表文章没有之一)](https://blog.csdn.net/Zhouzi_heng/article/details/127554294) 文章目录 需求分析 增加用户积分 获取TopN 特点分析 多级缓存 降级策略 如何应对海量数据? 策略1 压缩数据量 策略2 数据分片 策略3 数据预处理 ZSet 底层数据结构 参考链接 标签: 软件设计 转载请注明文章来源 本作品采用 知识共享署名-相同方式共享 4.0 国际许可协议 进行许可。
评论已关闭